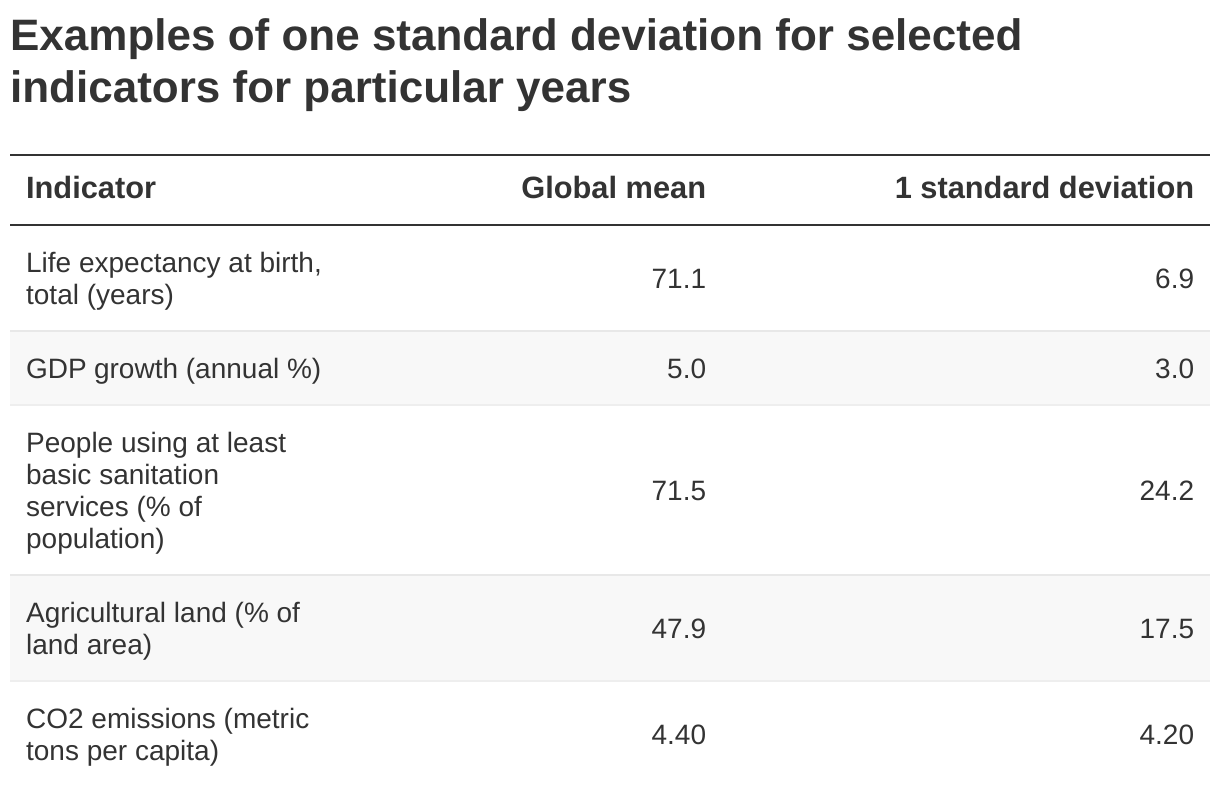
Por Daniel Gerszon Mahler Economista, Grupo de Datos de Desarrollo, Banco Mundial Umar Serajudín Gerente, Grupo de Datos de Desarrollo, Banco Mundial Hiroko Maeda Estadístico en el Banco Mundial Abra un periódico y es probable que encuentre alguna estadística global que se refiera a cómo le está yendo al mundo: "Se prevé que el crecimiento global se recupere", "el número de refugiados en todo el mundo aumentará por tercer año consecutivo", "emisiones globales de CO2". están alcanzando un máximo histórico”. La demanda de estadísticas mundiales quizás se materialice mejor en los Objetivos de Desarrollo Sostenible, cuyos 231 indicadores en su mayor parte pueden agregarse y se agregan a nivel mundial. Rara vez hay datos globales completos detrás de tales estadísticas. Por falta de recursos, capacidad y voluntad política, algunos países no producen información sobre los indicadores de interés. Al crear estadísticas globales, las estimaciones para estos países se imputan o simplemente se ignoran. Esto crea inevitablemente una compensación entre la disponibilidad de estadísticas globales y la precisión de estas estadísticas. Si las estadísticas globales solo se publican cuando los datos están disponibles de forma universal o casi universal, habrá muchos temas importantes que no se podrán esclarecer. Si se publican estadísticas globales incluso cuando la cobertura de datos es débil, la precisión de las estadísticas puede ser dudosa en el sentido de que es probable que se desvíen de la cifra si todos los datos estuvieran disponibles. En un nuevo Documento de Trabajo de Investigación de Políticas , cuantificamos esta compensación usando los Indicadores de Desarrollo Mundial . Seleccionamos 165 indicadores que abarcan una amplia gama de temas donde los datos están disponibles para al menos el 99% de la población mundial. Para estos 165 indicadores, eliminamos aleatoriamente un subconjunto de datos, calculamos el nuevo valor medio global y lo comparamos con el valor medio cuando se usan todos los datos. Esto nos da una estimación del error cuando solo una fracción de la población mundial tiene datos. Repitiendo este ejercicio más de 10 millones de veces utilizando diferentes indicadores y diferentes probabilidades de faltar, podemos calcular el error esperado en función de la cobertura de la población. Para comparar indicadores en diferentes unidades, estandarizamos todas las variables para que tengan media 0 y varianza 1. Esto nos permite expresar el error como desviaciones estándar de la media. Dado que la mayoría de los productores de datos pueden no estar acostumbrados a pensar en su indicador en términos de desviaciones estándar de la media, la siguiente tabla muestra lo que implica una desviación estándar para cinco indicadores. Si uno está a una desviación estándar de la verdadera media al crear una estadística global, se podría reducir la esperanza de vida en 7 años, el crecimiento global en 3 puntos porcentuales y la proporción que usa al menos servicios básicos de saneamiento en 24 puntos porcentuales. Incluso si estos errores se reducen en cuatro, y uno está a 0,25 de una desviación estándar de la verdad, siguen representando grandes errores. La siguiente figura muestra los resultados de nuestras simulaciones. El error esperado aumenta linealmente con la proporción de población sin datos. El ajuste lineal sugiere que si la proporción de la población mundial de la que se carece de datos es x, entonces se debe esperar que esté a 0,37*x desviaciones estándar de la media real. , con el límite superior de esta estimación aproximadamente x desviaciones estándar de la media real. Dicho a la inversa, si uno está dispuesto a tolerar que haya y desviaciones estándar lejos de la media real, entonces puede tolerar faltantes en y*2.7 (=y*1/0.37) de la población global. El amplio intervalo de confianza refleja que cuando solo se tienen datos de una parte de la población, se puede tener suerte y obtener la media correcta, o mala suerte y estar lejos. En otros resultados, mostramos cómo cambian estos errores (i) si uno está interesado en estadísticas regionales, (ii) si se imputan datos, (iii) si la probabilidad de que falten datos está correlacionada con el indicador de interés, (iv) si uno utiliza la proporción de países en lugar de la proporción de población como umbral de cobertura, y (v) si tiene requisitos de cobertura específicos para países poblados, como India. En conclusión, ofrecemos algunos consejos sobre cómo decidir cuándo hay suficientes datos para crear estadísticas globales. Lo más importante a tener en cuenta es que no existe un umbral único que pueda guiar cuándo publicar estadísticas globales o no. La decisión dependerá del contexto. En particular, creemos que el productor de datos debe hacerse las siguientes preguntas: ¿Cuántos errores estoy dispuesto a tolerar? ¿Qué tan generalizados son los datos faltantes en mis indicadores de interés? ¿Es probable que la probabilidad de que un país no tenga datos se correlacione con el indicador de interés? [Si se producen series de tiempo] ¿Cuánto cambian las estadísticas globales de un año a otro y los mismos países tienen valores faltantes constantemente? [Si se imputan los datos que faltan] ¿Qué confianza tengo en la precisión de las imputaciones? [Si se producen estadísticas subglobales] ¿De qué tamaño son los grupos y qué parte de la variación ocurre entre subgrupos en lugar de dentro de los subgrupos? A juzgar por la tabla que compara las desviaciones estándar con las unidades originales, nuestra opinión (ciertamente subjetiva) es que los errores nunca deberían superar las 0,25 desviaciones estándar. Incluso en los casos menos optimistas presentados en el documento, esto corresponde aproximadamente a no publicar estadísticas cuando se dispone de datos para menos de la mitad de la población relevante.